Last updated on May 5, 2020

The 45th President of the USA
Introduction
The problem of predicting election outcomes with social media is that the data, such as likes, are aggregate, whereas the election system is not — apart from simple majority voting, in which you only have the classic representativeness problem that Gallup solved in 1936.
To solve the aggregation problem, one needs to segment the polling data so that it 1) corresponds to the prevailing election system and 2) accurately reflects the voters according to that system. For example, in the US presidential election each state has a certain number of electoral votes. To win, a candidate needs to reach 270 electoral votes.
Disaggregating the data
One obvious solution would be track like sources to profiles and determine the state based on publically given information by the user. This way we could filter out foreign likers as well. However, there are some issues of using likes as indicators of votes. Most importantly, “liking” something on social media does not in itself predict future behavior of an individual to a sufficient degree.
Therefore, I suggest here a simple polling method via social media advertising (Facebook Ads) and online surveys (Survey Monkey). Polling is partly facing the same aforementioned problem of future behavior than using likes as the overarching indicator which is why in the latter part of this article I discuss how these approaches could be combined.
At this point, it is important to acknowledge that online polling does have significant advantages relating to 1) anonymity, 2) cost, and 3) speed.
That is, people may feel more at ease expressing their true sentiment to a machine than another human being. Second, the method has the potential to collect a sizeable sample in a more cost-effective fashion than calling.
Finally, a major advantage is that due to the scalable nature of online data collection, the predictions can be updated faster than via call-based polling. This is particularly important because election cycles can involve quick and hectic turns. If the polling delay is from a few days to a week, it is too late to react to final week events of a campaign which may still carry a great weight in the outcome.
In other words: the fresher the data, the better. (An added bonus is that by doing several samples, we could consider momentum i.e. growth speed of a candidate’s popularity into our model – albeit this can be achieved with traditional polling as well.)
Social media polling (SMP)
The method, social media polling or SMP, is described in the following picture.
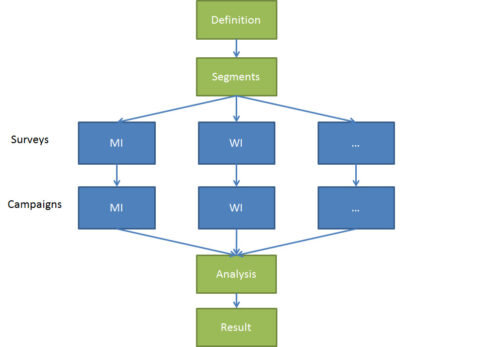
Figure 1 Social media polling
The process:
1. Define segmentation criteria
First, we understand the election system. For example, in the US system every state has a certain weight expressed by its share of total electoral votes. There are 50 states, so these become our segmentation criteria. In case we deem appropriate to do further segmentation (e.g., gender, age), we can do so by creating additional segments which are reflected in target groups and surveys. (These sub-segments can also be analyzed in the actual data later on.)
2. Create unique surveys
Then, we create a unique survey for each segment so that the answers will be bucketed. The questions of the survey are identical – they are just behind different links to enable easy segmentation. We create a survey rather than use a visible poll (app) or picture-type of poll (“like if you vote Trump, heart if you vote Hillary”), because we want to avoid social desirability bias. A click on Facebook will lead the user to the unique survey of their segment, and their answers won’t be visible to the public.
3. Determine sample size
Calculating sample size is one of those things that will make your head spin, because there’s no easy answer as to what is a good sample size. Instead, “it depends.” However, we can use some heuristical rules to come up with decent alternatives in the context of elections. Consider two potential sample sizes.
- Sample size: 500
- Confidence level: 95%
- Margin of error: +/- 4.4%
- Sample size: 1,000
- Confidence level: 95%
- Margin of error: +/- 3%
These are seen as decent options among election pollsters. However, the margin of error is still quite sizeable in both of them. For example, if there are two candidates and their “true” support values are A=49%, B=51%, the large margin of error makes us easily go wrong.
We could solve this by increasing the sample size, but the problem is that if we would like to reduce the margin of error from +/- 3% to say 1%, our required sample size grows dramatically (more precisely, with a 95% confidence and population size of 1M, it’s 9512 – unpractically high for a 50-state model). In other words, we have to accept the risk of wrong predictions in this type of situation.
All states have over 1,000,000 million people so each of them are considered as “large” populations (this is a mathematical thing – required sample size stabilizes after reaching a certain population size). Although US is characterized as one population, in the context of election prediction it’s actually several different populations (because we have independent states that vote).
The procedure we apply is stratified random sampling in which the large general population is split into sub-groups. In practice, each sub-group requires its own sample, and therefore our approach requires a considerably larger sample size than a prediction that would only consider the whole population of the country. But, exactly because of this it should be more accurate.
So, with this lengthy explanation let us say we satisfice with a sample size of 500 per state. That would be 500×50=25,000 respondents. If it would cost 0.60$ to get a respondent via running Facebook ads, the cost for data collection would be 15,000$. For repetitive purposes, there are a few strategies.
First, the sample size can be reduced for states that show a large difference between the candidates. In other words, we don’t need to collect a large number of respondents if we “know” the popularity difference between candidates is high. The important thing is that the situation is measured periodically, and sample sizes are flexibly adjusted according to known results.
In a similar vein, we can increase the sample size for states where the competition is tight, to reduce the margin of error and therefore to increase the accuracy of our prediction. To my understanding, the opportunity of flexible sampling is not efficiently used by all pollsters.
4. Create Facebook campaigns
For each segment, a target group is created in Facebook Ads. The target group is used to advertise to that particular group; for example, the Michigan survey link is only shown to people from Michigan. That way, we minimize the risk of people outside the segment responding (however, they can excluded later on by IP). At this stage, creating attractive ads help keeping the cost per response low.
5. Run until sample size is reached
The administrator observes the results and stops the data collection once a segment has reached the desired sample size. When all segments are ready, the data collection is stopped.
6. Verify data
Based on IP, we can filter out respondent who do not belong to our particular geographical segment (=state).
Ad clicks can be used to determine sample representativeness by other factors – in other words, we can use Facebook’s campaign reports to segment age and gender information. If a particular group is under-represented, we can correct by altering the targeting towards them and resume data collection.
However, we can also accept the under-representation if we have no valid reference model as to voting behavior of the sub-segments. For example, millennials might be under-represented in our data, but this might correspond with their general voting behavior as well – if we assume survey response rate corresponds with voting rate of the segments, then there is no problem.
7. Analyze results
The analysis process is straight-forward:
segment-level results x weights = prediction outcome
For example, in the US presidential election, segment-level results would be each state (who polls highest in the state is the winner there) which would be multiplied by the share of electoral votes of each state. The candidate who gets at least 270 votes is the predicted winner.
Other methods
Now, as for other methods, we can use behavioral data. I have previously argued behavioral data is a stronger indicator of future actions since it’s free from reporting bias. In other words, people say they do, but won’t end up doing. This is a very common problem, but in research and daily life.
To correct for that, we consider two approaches here:
1) The volume of likes method, which parallels a like to a vote (the more likes a candidate has in relation to another candidate, the more likely they are to win)
For this method to work, the “intensity of like”, i.e. its correlation to behavior should be determined, as not all likes are indicators of voting before. Likes don’t readily translate into votes, and there does not appear to be other information we can use to further examine their correlation (like is a like). We could, however, add contextual information of the person, or use rules such as “the more likes a person gives, the more likely (s)he is to vote for a candidate.”
Or, we could use another solution which I think is better:
2) Text analysis/mining
By analyzing social media comments of a person, we can better infer the intensity of their attitude towards a given topic (in this case, a candidate). If a person is using strongly positive vocabulary while referring to a candidate, then (s)he is more likely to vote for him/her than if the comments are negative or neutral.
Notice that the mere positive-negative range is not enough, because positivity has degrees of intensity we have to consider. It is different to say “he is okay” than “omg he is god emperor”. The more excitement and associated feelings – which need to be carefully mapped and defined in the lexicon – a person exhibits, the more likely voting behavior is.
Limitations
As I mentioned, even this approach risks shortcoming of representativeness. First, the population on Facebook may not correspond with the population at large. It may be that the user base is skewed by age or some other factor. The choice of platform greatly influences the sample; for example, SnapChat users are on average younger than Facebook users, whereas Twitter users are more liberal. It is not clear whether Facebook’s user base represents a skewed sample or not.
Second, the people voicing their opinions may be part of “vocal minority” as opposed to “silent majority”. In that case, we apply the logic of Gaussian standard distribution and assumed that the general population is more lenient to middle ground than the extremes — if, in addition, we would assume the central tendency to be symmetrical (meaning people in the middle are equally likely to tip into either candidate in a dual race), the analysis of extremes can still yield a valid prediction.
Another limitation may be that advertising targeting is not equivalent to random sampling, but has some kind of bias. That bias could emerge e.g. from 1) ad algorithm favoring a particular sub-set of the target group, i.e. showing more ads to them, whereas we would like to get all types of respondents; or 2) self-selection in which the respondents are of similar kind and again not representative to the population.
Out of my head, I’d say number two is less of a problem because those people who show enough interest are also the ones who vote – remember, essentially we don’t need to care about the opinions of the people who don’t vote (that’s how elections work!).
But number one could be a serious issue, because ad algorithm directs impressions based on responses and might identify some hidden pattern we have no control over. Basically, the only thing we can do is examine superficial segment information on the ad reports, and evaluate if the ad rotation was sufficient or not.
Combining different approaches
As both approaches – traditional polling and social media analysis – have their shortcomings and advantages, it might be feasible to combine the data under a mixed model which would factor in 1) count of likes, 2) count of comments with high affinity (=positive sentiment), and 3) polled preference data.
A deduplicating process would be needed to not count twice those who liked and commented – this requires associating likes and comments to individuals. Note that the hybrid approach requires geographic information as well, because otherwise segmentation is diluted. Anyhow, taking user as the central entity could be a step towards determining voting propensity:
user (location, count of likes, count of comments, comment sentiment) –> voting propensity
Another way to see this is that enriching likes with relevant information (in regards to the election system) can help model social media data in a more granular and meaningful way.