Last updated on May 5, 2020

Introduction
Had an interesting chat with Sami Kuusela from Underhood.co. Based on that, got some inspiration for an analysis framework which I’ll briefly describe here.
The model
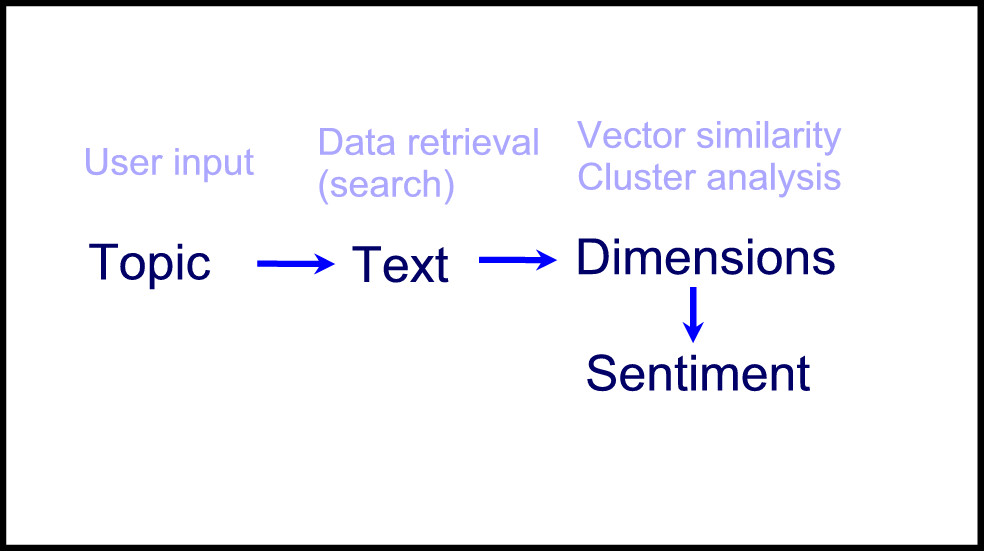
Figure 1 Identifying and analyzing topical text material
The description
- User is interested in a given topic (e.g., Saara Aalto, or #saaraaalto). He enters the relevant keywords.
- The system runs a search and retrieves text data based on that (e.g., tweets).
- A cluster analysis (e.g., unsupervised topic model) identifies central themes from the data.
- Vectorization of representative keywords based on cluster analysis (e.g., 10 most popular) is run to extract words from a reference lexicon of words that have a similar meaning. This increases the generality of each topic cluster by associating them with other words that are close in the vector space.
- Text mining is run to refine the themes, i.e. placing the right text pieces under the correct themes. These are now called “dimensions”, since they describe the key dimensions of the text corpus (e.g., Saara’s voice, performance, song choices…).
- Sentiment analysis can be run to score the general (pos/neg/neu) or specific (e.g., emotions: joy, excitement, anger, disappointment, etc.) sentiment of each dimension. This could be done by using a machine-learning model with annotated training data (if the data-set is vast), or some sentiment lexicon (if the data-set is small).
I’m not sure whether steps 4 and 5 would improve the system’s ability to identify topics. It might be that a more general model is not required because the system already can detect the key themes. Would be interesting to test this with a developer.
Anyway, what’s the whole point?
The whole point is to acknowledge that each large topic naturally divides into small sub-topics, which are dimensions that people perceive relevant for that particular topic. For example, in politics it could be things like “economy”, “domestic policy”, “immigration”, “foreign policy”, etc. While the dimensions can have some consistency based on the field, e.g. all political candidates share some dimensions, the exact mix is likely to be unique, e.g. dimensions of social media texts relating to Trump are likely to be considerably different from those of Clinton. That’s why the analysis ultimately needs to be done case-by-case.
In any case, it is important to note that instead of giving a general sentiment or engagement score of, say a political candidate, we can use an approach like this to give a more in-depth or segmented view of them. This leads to better understanding of “what works or not”, which is information that can be used in strategic decision-making. In addition, the topic-segmented sentiment data could be associated with predictors in a predictive model, e.g. by multiplying each topic sentiment with the weight of the respective topic (assuming the topic corresponds with the predictor).
Limitations
This is just a conceptual model. As said, would be interesting to test it. There are many potential issues, such as handling with cluster overlap (some text pieces can naturally be placed into several clusters which can cause classification problems) and hierarchical issues (e.g., “employment” is under “economy” and should hence influence the former’s sentiment score).