Last updated on May 5, 2020

Introduction
I ran an analysis with IBM Watson Personality Insights. It retrieved my tweets and analyzed their text content to describe me as a person.
Doing so is easy – try it here: https://personality-insights-livedemo.mybluemix.net/
I’ll briefly discuss the accuracy of the findings in this post.
TL;DR: The accuracy of IBM Watson is a split decision – some classifications seem to be accurate, while others are not. The inaccuracies are probably due to lack of source material exposing a person’s full range of preferences.
Findings
The tool analyzed 25,082 words and labelled the results as “Very Strong Analysis”. In the following, I will use introspection to comment the accuracy of the findings.
“You are a bit critical, excitable and expressive.”
Introspection: TRUE
“You are philosophical: you are open to and intrigued by new ideas and love to explore them. You are proud: you hold yourself in high regard, satisfied with who you are. And you are authority-challenging: you prefer to challenge authority and traditional values to help bring about positive changes.”
Introspection: TRUE
“Your choices are driven by a desire for efficiency.”
Introspection: TRUE
“You are relatively unconcerned with both tradition and taking pleasure in life. You care more about making your own path than following what others have done. And you prefer activities with a purpose greater than just personal enjoyment.”
Introspection: TRUE
At this point, I was very impressive with the tool. So far, I would completely agree with its assessment of my personality, although it’s only using my tweets which are short and mostly shared links.
While the description given by Watson Personality Insights was spot on (introspection agreement: 100%), I found the categorical evaluation to be lacking. In particular, “You are likely to______”
“be concerned about the environment”
Introspection: FALSE (I am not particularly concerned about the environment, as in nature, although I am worried about societal issues like influence of automation on jobs, for example)
“read often”
Introspection: TRUE
“be sensitive to ownership cost when buying automobiles”
Introspection: TRUE
Actually, the latter one is quite amazing because it describes my consumption patterns really well. I’m a very frugal consumer, always taking into consideration the lifetime cost of an acquisition (e.g., of a car).
In addition, the tool tells also that “You are unlikely to______”
“volunteer to learn about social causes”
Introspection: TRUE
“prefer safety when buying automobiles”
Introspection: FALSE (In fact, I’m thinking of buying a car soon and safety is a major criteria since the city I live in has rough traffic.)
“like romance movies”
Introspection: FALSE (I do like them! Actually just had this discussion with a friend offline, which is a another funny coincidence.)
So, the overall accuracy rate here is only 3/6 = 50%.
I did not read into the specification in more detail, but I suspect the system chooses the evaluated categories based on the available amount of data; i.e. it simply leaves off topics with inadequate data. Since there is a very broad number of potential topics (ranging from ‘things’ to ‘behaviors’), the probability of accumulating enough data points on some topics increases as the amount of text increases. In other words, you are more likely to hit some categories and, after accumulating enough data on them, you can present quite a many descriptors about the person (while simply leaving out those you don’t have enough information on).
However, the choice of topics was problematic: I have never tweeted anything relating to romantic movies (at least to my recall) which is why it’s surprising that the tool chose it as a feature. The logic must be: “in absence of Topic A, there is no interest in Topic A” which is somewhat fallible given my Twitter behavior (= leaning towards professional content). Perhaps this is the root of the issue – if my tweets had a higher emphasis on movies/entertainment, it could better predict my preferences. But as of now, it seems the system has some gaps in describing the full spectrum of a user’s preferences.
Finally, Watson Personality Insights gives out numerical scores for three dimensions: Personality, Consumer needs, and Values. My scores are presented in the following figure.
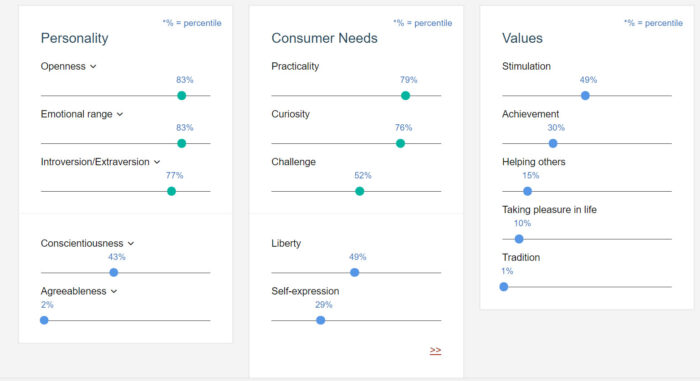
Figure 1 IBM Watson Personality Scores
I won’t go through all of them here, but the verdict here is also split. Some are correct, e.g. practicality and curiousity, while others I would say are false (e.g., liberty, tradition). In sum, I would say it’s more accurate than not (i.e., beats chance).
Conclusion
The system is surprisingly accurate given the fact it is analyzing unstructured text. It would be interesting to know how the accuracy fares in comparison to personality scales (survey data). This is because those scales rely on structured form of inquiry which has less noise, at least in theory. In addition, survey scales may result in a comprehensive view of traits, as all the traits can be explicitly asked about. Social media data may systematically miss certain expressions of personality: for example, my tweets focus on professional content and therefore are more likely to misclassify my liking of romantic movies – a survey could explicitly ask both my professional and personal likings, and therefore form a more balanced picture.
Overall, it’s exciting and even a bit scary how well a machine can describe you. The next step, then, is how could the results be used? Regardless of all the hype surrounding the Cambridge Analytica’s ability to “influence the election”, in reality combining marketing messages with personality descriptions is not straight-forward as it may seem. This is because preferences are much more complex than just saying you are of personality type A, therefore you approve message B. Most likely, the inferred personality traits are best used as additional signals or features in decision-making situations. They are not likely to be only ones, or even the most important ones, but have the potential to improve models and optimization outcomes for example in marketing.